Advancing the dynamic loco-manipulation capabilities of quadruped robots in complex terrains is crucial for performing diverse tasks. Specifically, dynamic ball manipulation in rugged environments presents two key challenges. The first is coordinating distinct motion modalities to integrate terrain traversal and ball control seamlessly. The second is overcoming sparse rewards in end-to-end reinforcement learning, which impedes efficient policy convergence. To address these challenges, we propose a hierarchical reinforcement learning framework. A high-level policy, informed by proprioceptive data and ball position, adaptively switches between pre-trained low-level skills such as ball dribbling and rough terrain navigation. We further propose Dynamic Skill-Focused Policy Optimization to suppress gradients from inactive skills and enhance critical skill learning. Both simulation and real-world experiments validate that our methods outperform baseline approaches in dynamic ball manipulation across rugged terrains, highlighting its effectiveness in challenging environments.
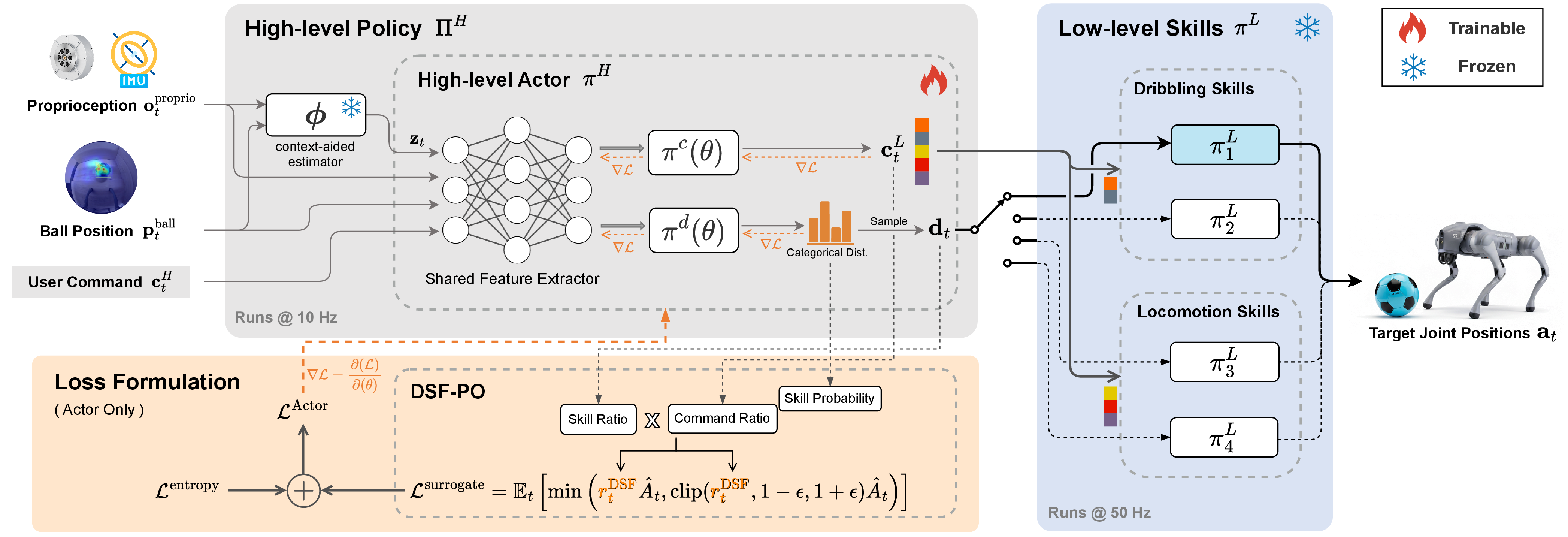
We propose a hierarchical reinforcement learning (HRL) framework that comprises two parts:
We conduct extensive experiments, including one that evaluates our algorithm to dribble on a variety of complex terrains.
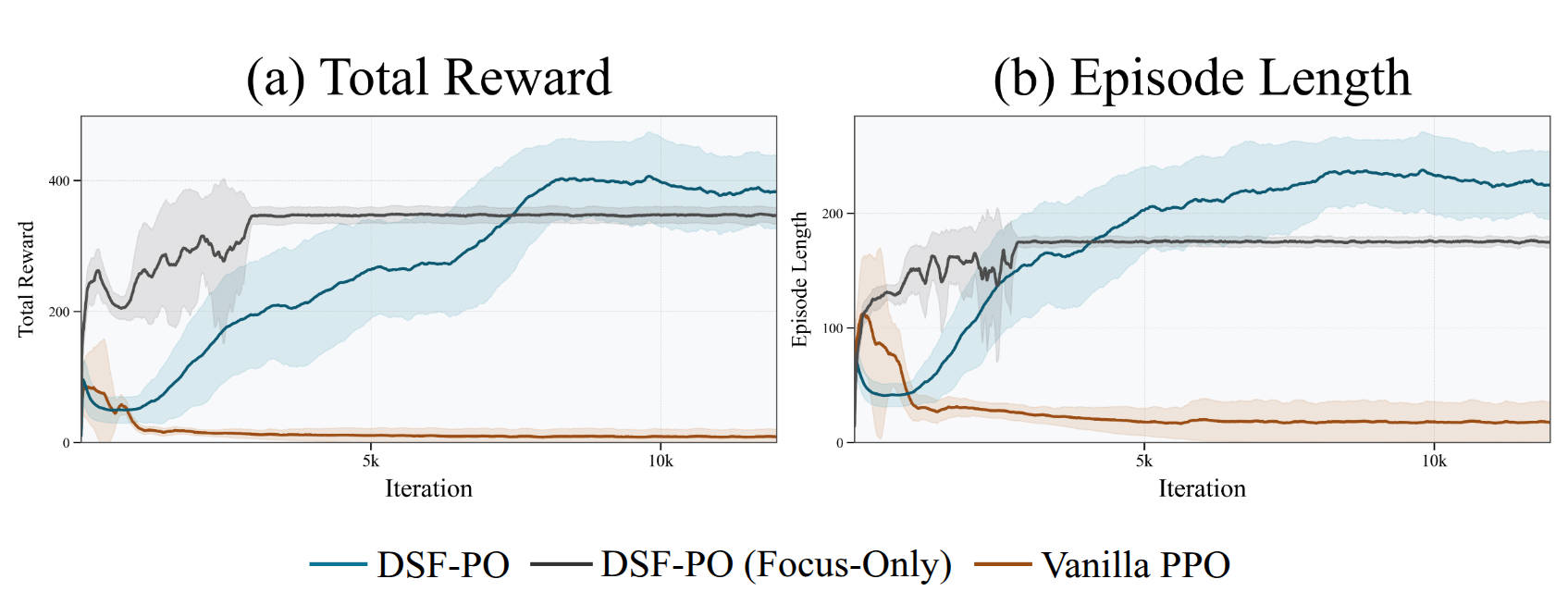
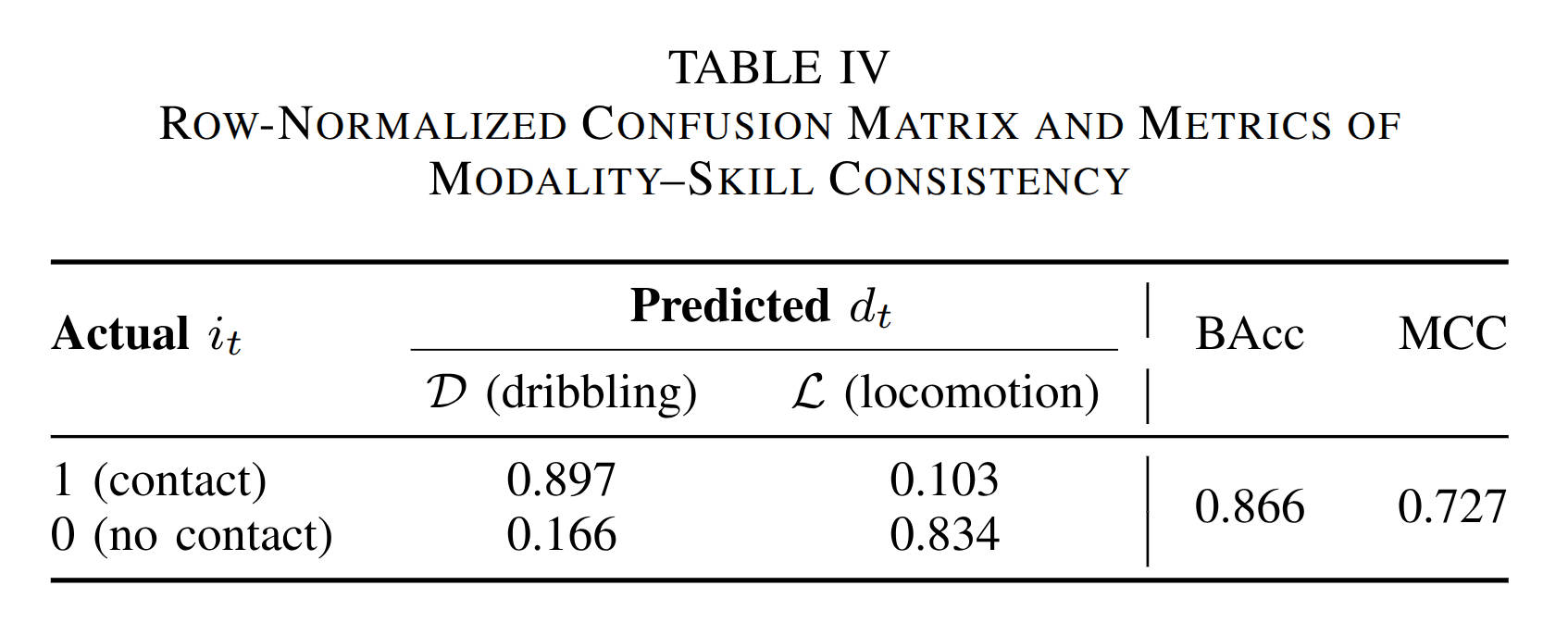
We also conduct a series of ablation studies on our proposed algorithm and perform modality-skill consistency checks.
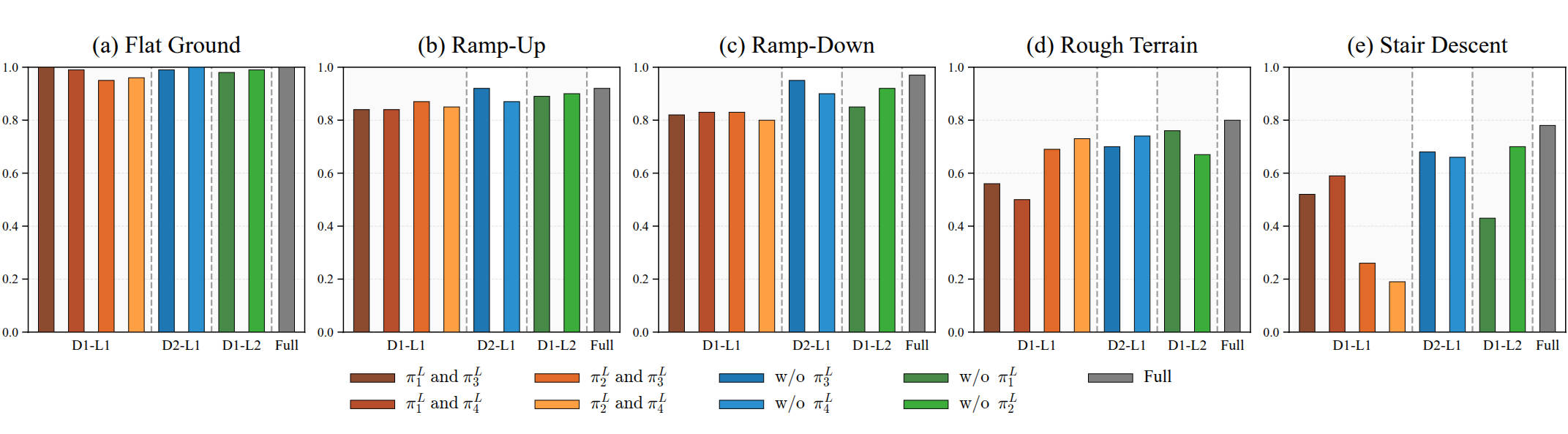
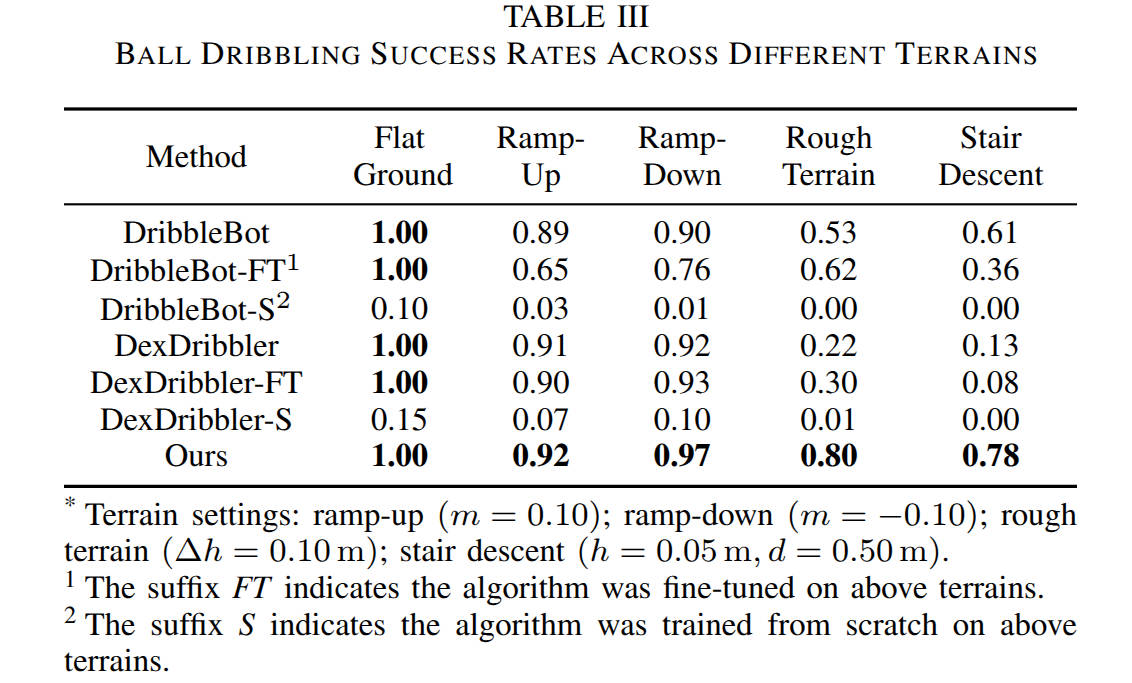
We use a Unitree Go2 quadruped robot, which is additionally equipped with a downward-facing fisheye camera featuring a 240° field-of-view mounted on its head. All policy inference runs onboard with an NVIDIA Jetson Orin NX. We evaluate our policy on the following terrains.

@misc{zhu2025dynamicleggedballmanipulation,
title={Dynamic Legged Ball Manipulation on Rugged Terrains with Hierarchical Reinforcement Learning},
author={Dongjie Zhu and Zhuo Yang and Tianhang Wu and Luzhou Ge and Xuesong Li and Qi Liu and Xiang Li},
year={2025},
eprint={2504.14989},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2504.14989},
}